
神经网络基础知识
神经元的数学模型
神经网络由基本的神经元组成,图NeuranCell 就是一个神经元的数学/计算模型。

输入 input
$(x_1,x_2,x_3)$ 是外界输入信号,一般是一个训练数据样本的多个属性。
权重 weights
$(w_1,w_2,w_3)$ 是每个输入信号的权重值,以上面的 $(x_1,x_2,x_3)$ 的例子来说,$x_1$ 的权重可能是 $0.92$,$x_2$ 的权重可能是 $0.2$,$x_3$ 的权重可能是 $0.03$。当然权重值相加之后可以不是 $1$。
偏移 bias
还有个 $b$ 是怎么来的?一般的书或者博客上会告诉你那是因为 $y=wx+b$,$b$ 是偏移值,使得直线能够沿 $Y$ 轴上下移动。这是用结果来解释原因,并非 $b$ 存在的真实原因。从生物学上解释,在脑神经细胞中,一定是输入信号的电平/电流大于某个临界值时,神经元细胞才会处于兴奋状态,这个 $b$ 实际就是那个临界值。亦即当:
$$w_1 \cdot x_1 + w_2 \cdot x_2 + w_3 \cdot x_3 \geq t$$
时,该神经元细胞才会兴奋。我们把t挪到等式左侧来,变成$(-t)$,然后把它写成 $b$,变成了:
$$w_1 \cdot x_1 + w_2 \cdot x_2 + w_3 \cdot x_3 + b \geq 0$$
于是 $b$ 诞生了!
求和计算 sum
$$
\begin{aligned}
Z &= w_1 \cdot x_1 + w_2 \cdot x_2 + w_3 \cdot x_3 + b \\
&= \sum_{i=1}^m(w_i \cdot x_i) + b
\end{aligned}
$$
在上面的例子中 $m=3$。我们把$w_i \cdot x_i$变成矩阵运算的话,就变成了:
$$Z = W \cdot X + b$$
激活函数 activation
求和之后,神经细胞已经处于兴奋状态了,已经决定要向下一个神经元传递信号了,但是要传递多强烈的信号,要由激活函数来确定:
$$A=\sigma{(Z)}$$
如果激活函数是一个阶跃信号的话,会像继电器开合一样咔咔的开启和闭合,在生物体中是不可能有这种装置的,而是一个渐渐变化的过程。所以一般激活函数都是有一个渐变的过程,也就是说是个曲线,如图activation 所示。

训练流程
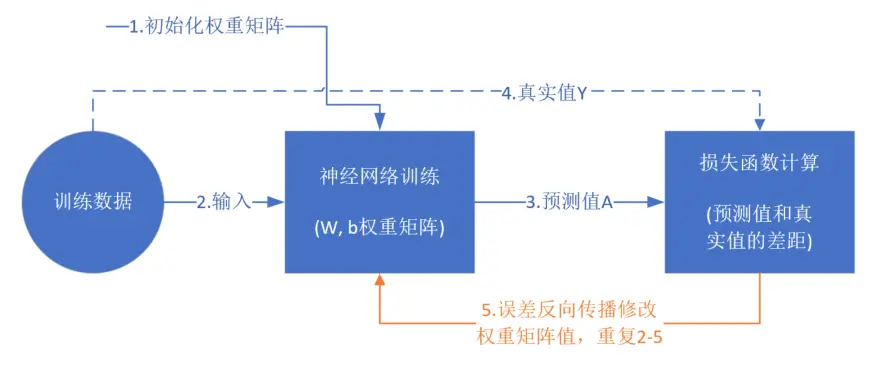
反向传播
反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。该方法对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。
正向计算的实例
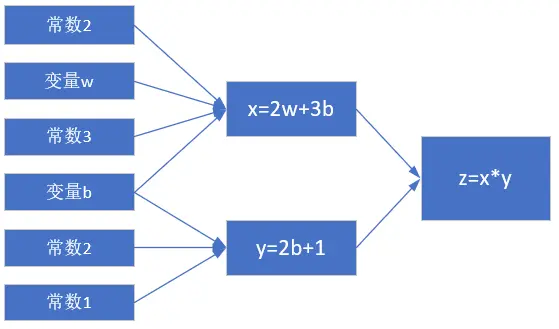
假设有一个函数:
$$z = x \cdot y \tag{1}$$
其中:
$$x = 2w + 3b \tag{2}$$
$$y = 2b + 1 \tag{3}$$
当 $w = 3, b = 4$ 时,会得到图flow2 的结果。
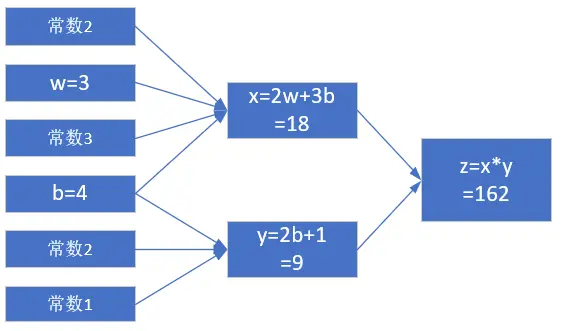
最终的 $z$ 值,受到了前面很多因素的影响:变量 $w$,变量 $b$,计算式 $x$,计算式 $y$。
反向传播求解 $w$
求 $w$ 的偏导
假设目标 $z=150$,先只考虑改变 $w$ 的值,而令 $b$ 值固定为 $4$。
因为 $$z = x \cdot y$$,其中 $$x = 2w + 3b, y = 2b + 1$$
所以:
$$\frac{\partial{z}}{\partial{w}}=\frac{\partial{z}}{\partial{x}} \cdot \frac{\partial{x}}{\partial{w}}=y \cdot 2=18 \tag{4}$$
其中:
$$\frac{\partial{z}}{\partial{x}}=\frac{\partial{}}{\partial{x}}(x \cdot y)=y=9$$
$$\frac{\partial{x}}{\partial{w}}=\frac{\partial{}}{\partial{w}}(2w+3b)=2$$

求 $w$ 的具体变化值
公式4的含义是:当 $w$ 变化一点点时,$z$ 会产生 $w$ 的变化值18倍的变化。记住我们的目标是让 $z=150$,目前在初始状态时是 $z=162$,所以,问题转化为:当需要 $z$ 从 $162$ 变到 $150$ 时,$w$ 需要变化多少?
既然:
$$
\Delta z = 18 \cdot \Delta w
$$
则:
$$
\Delta w = {\Delta z \over 18}=\frac{162-150}{18}= 0.6667
$$
所以:
$$w = w - 0.6667=2.3333$$
$$x=2w+3b=16.6667$$
$$z=x \cdot y=16.6667 \times 9=150.0003$$
我们一下子就成功地让 $z$ 值变成了 $150.0003$,与 $150$ 的目标非常地接近,这就是偏导数的威力所在。
反向传播求解 $b$
求 $b$ 的偏导
目标还是让 $z=150$,这次我们令 $w$ 的值固定为 $3$,变化 $b$ 的值。
从复合导数公式来看,这两者应该是相加的关系,所以有:
$$\frac{\partial{z}}{\partial{b}}=\frac{\partial{z}}{\partial{x}} \cdot \frac{\partial{x}}{\partial{b}}+\frac{\partial{z}}{\partial{y}}\cdot\frac{\partial{y}}{\partial{b}}=y \cdot 3+x \cdot 2=63 \tag{5}$$
其中:
$$\frac{\partial{z}}{\partial{x}}=\frac{\partial{}}{\partial{x}}(x \cdot y)=y=9$$
$$\frac{\partial{z}}{\partial{y}}=\frac{\partial{}}{\partial{y}}(x \cdot y)=x=18$$
$$\frac{\partial{x}}{\partial{b}}=\frac{\partial{}}{\partial{b}}(2w+3b)=3$$
$$\frac{\partial{y}}{\partial{b}}=\frac{\partial{}}{\partial{b}}(2b+1)=2$$
求 $b$ 的具体变化值
公式5的含义是:当 $b$ 变化一点点时,$z$ 会发生 $b$ 的变化值 $63$ 倍的变化。记住我们的目标是让 $z=150$,目前在初始状态时是 $162$,所以,问题转化为:当我们需要 $z$ 从 $162$ 变到 $150$ 时,$b$ 需要变化多少?
既然:
$$\Delta z = 63 \cdot \Delta b$$
则:
$$
\Delta b = \frac{\Delta z}{63}=\frac{162-150}{63}=0.1905
$$
所以:
$$
b=b-0.1905=3.8095
$$
$$x=2w+3b=17.4285$$
$$y=2b+1=8.619$$
$$z=x \cdot y=17.4285 \times 8.619=150.2162$$
这个结果也是与 $150$ 很接近了,但是精度还不够。再迭代几次,直到误差不大于 1e-4 时,我们就可以结束迭代了,对于计算机来说,这些运算的执行速度很快。

同时求解 $w$ 和 $b$ 的变化值
这次我们要同时改变 $w$ 和 $b$,到达最终结果为 $z=150$ 的目的。
已知 $\Delta z=12$,我们不妨把这个误差的一半算在 $w$ 的账上,另外一半算在 $b$ 的账上:
$$\Delta b=\frac{\Delta z / 2}{63} = \frac{12/2}{63}=0.095$$
$$\Delta w=\frac{\Delta z / 2}{18} = \frac{12/2}{18}=0.333$$
- $w = w-\Delta w=3-0.333=2.667$
- $b = b - \Delta b=4-0.095=3.905$
- $x=2w+3b=2 \times 2.667+3 \times 3.905=17.049$
- $y=2b+1=2 \times 3.905+1=8.81$
- $z=x \times y=17.049 \times 8.81=150.2$
注意:
- 在检查 $\Delta z$ 时的值时,注意要用绝对值,因为有可能是个负数
- 在计算 $\Delta b$ 和 $\Delta w$ 时,第一次时,它们对 $z$ 的贡献值分别是 $1/63$ 和 $1/18$,但是第二次时,由于 $b,w$ 值的变化,对 $z$ 的贡献值也会有微小变化,所以要重新计算。具体解释如下:
$$
\frac{\partial{z}}{\partial{b}}=\frac{\partial{z}}{\partial{x}} \cdot \frac{\partial{x}}{\partial{b}}+\frac{\partial{z}}{\partial{y}}\cdot\frac{\partial{y}}{\partial{b}}=y \cdot 3+x \cdot 2=3y+2x
$$$$
\frac{\partial{z}}{\partial{w}}=\frac{\partial{z}}{\partial{x}} \cdot \frac{\partial{x}}{\partial{w}}+\frac{\partial{z}}{\partial{y}}\cdot\frac{\partial{y}}{\partial{w}}=y \cdot 2+x \cdot 0 = 2y
$$所以,在每次迭代中,要重新计算下面两个值:
$$
\Delta b=\frac{\Delta z}{3y+2x}
$$$$
\Delta w=\frac{\Delta z}{2y}
$$
python代码:
1 | import numpy as np |
运行结果:

非线性反向传播
例:

其中$1<x<=10,0<y<2.15$。假设有5个人分别代表 $x,a,b,c,y$:
正向过程
- 第1个人,输入层,随机输入第一个 $x$ 值,$x$ 的取值范围 $(1,10]$,假设第一个数是 $2$;
- 第2个人,第一层网络计算,接收第1个人传入 $x$ 的值,计算:$a=x^2$;
- 第3个人,第二层网络计算,接收第2个人传入 $a$ 的值,计算:$b=\ln (a)$;
- 第4个人,第三层网络计算,接收第3个人传入 $b$ 的值,计算:$c=\sqrt{b}$;
- 第5个人,输出层,接收第4个人传入 $c$ 的值
反向过程
- 第5个人,计算 $y$ 与 $c$ 的差值:$\Delta c = c - y$,传回给第4个人
- 第4个人,接收第5个人传回$\Delta c$,计算 $\Delta b = \Delta c \cdot 2\sqrt{b}$
- 第3个人,接收第4个人传回$\Delta b$,计算 $\Delta a = \Delta b \cdot a$
- 第2个人,接收第3个人传回$\Delta a$,计算 $\Delta x = \frac{\Delta}{2x}$
- 第1个人,接收第2个人传回$\Delta x$,更新 $x \leftarrow x - \Delta x$,回到第1步
$$
\frac{da}{dx}=\frac{d(x^2)}{dx}=2x=\frac{\Delta a}{\Delta x} \tag{1}
$$$$
\frac{db}{da} =\frac{d(\ln{a})}{da} =\frac{1}{a} = \frac{\Delta b}{\Delta a} \tag{2}
$$$$
\frac{dc}{db}=\frac{d(\sqrt{b})}{db}=\frac{1}{2\sqrt{b}}=\frac{\Delta c}{\Delta b} \tag{3}
$$因此得到如下一组公式,可以把最后一层 $\Delta c$ 的误差一直反向传播给最前面的 $\Delta x$,从而更新 $x$ 值:
$$
\Delta c = c - y \tag{4}
$$$$
\Delta b = \Delta c \cdot 2\sqrt{b} \tag{根据式3}
$$$$
\Delta a = \Delta b \cdot a \tag{根据式2}
$$$$
\Delta x = \Delta a / 2x \tag{根据式1}
$$
提出问题:假设我们想最后得到 $c=2.13$ 的值,$x$ 应该是多少?(误差小于 $0.001$ 即可)
我们给定初始值 $x=2$,$\Delta x=0$,依次计算结果如表2-2。
| 方向 | 公式 | 迭代1 | 迭代2 | 迭代3 | 迭代4 | 迭代5 |
|---|---|---|---|---|---|---|
| 正向 | $x=x-\Delta x$ | 2 | 4.243 | 7.344 | 9.295 | 9.665 |
| 正向 | $a=x^2$ | 4 | 18.005 | 53.934 | 86.404 | 93.233 |
| 正向 | $b=\ln(a)$ | 1.386 | 2.891 | 3.988 | 4.459 | 4.535 |
| 正向 | $c=\sqrt{b}$ | 1.177 | 1.700 | 1.997 | 2.112 | 2.129 |
| 标签值y | 2.13 | 2.13 | 2.13 | 2.13 | 2.13 | |
| 反向 | $\Delta c = c - y$ | -0.953 | -0.430 | -0.133 | -0.018 | |
| 反向 | $\Delta b = \Delta c \cdot 2\sqrt{b}$ | -2.243 | -1.462 | -0.531 | -0.078 | |
| 反向 | $\Delta a = \Delta b \cdot a$ | -8.973 | -26.317 | -28.662 | -6.698 | |
| 反向 | $\Delta x = \Delta a / 2x$ | -2.243 | -3.101 | -1.951 | -0.360 |
python代码:
1 | import numpy as np |
运行结果:


梯度下降
梯度下降(英语:Gradient descent)是一个一阶最优化算法,通常也称为最陡下降法,但是不该与近似积分的最陡下降法(英语:Method of steepest descent)混淆。 要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。如果相反地向梯度正方向迭代进行搜索,则会接近函数的局部极大值点;这个过程则被称为梯度上升法。
梯度下降的数学理解
梯度下降的数学公式:
$$\theta_{n+1} = \theta_{n} - \eta \cdot \nabla J(\theta) \tag{1}$$
其中:
- $\theta_{n+1}$:下一个值;
- $\theta_n$:当前值;
- $-$:减号,梯度的反向;
- $\eta$:学习率或步长,控制每一步走的距离,不要太快以免错过了最佳景点,不要太慢以免时间太长;
- $\nabla$:梯度,函数当前位置的最快上升点;
- $J(\theta)$:函数。
梯度下降的三要素
- 当前点;
- 方向;
- 步长。
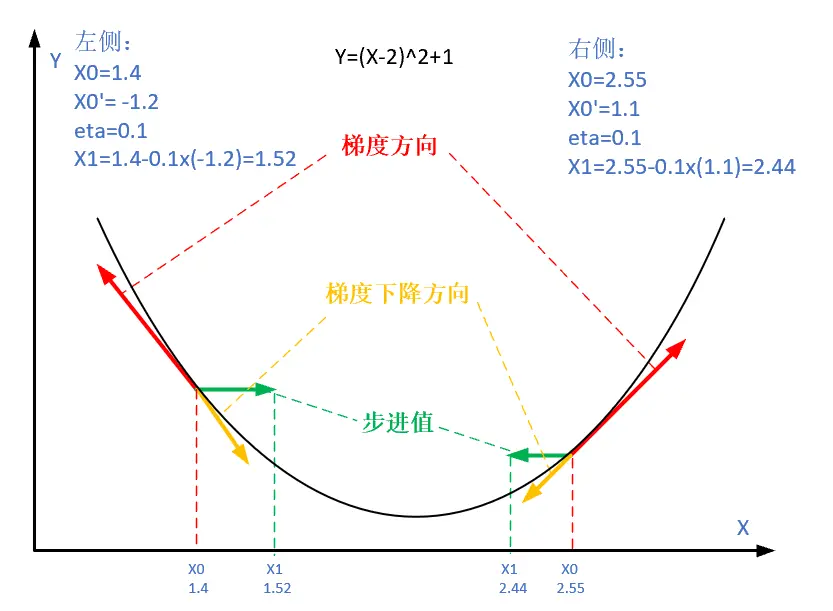
图gd_concept 解释了在函数极值点的两侧做梯度下降的计算过程,梯度下降的目的就是使得x值向极值点逼近。
单变量函数的梯度下降
假设一个单变量函数:
$$J(x) = x ^2$$
我们的目的是找到该函数的最小值,于是计算其微分:
$$J’(x) = 2x$$
假设初始位置为:
$$x_0=1.2$$
假设学习率:
$$\eta = 0.3$$
根据公式(1),迭代公式:
$$x_{n+1} = x_{n} - \eta \cdot \nabla J(x)= x_{n} - \eta \cdot 2x$$
假设终止条件为 $J(x)<0.01$
python代码:
1 | import numpy as np |
运行结果:


双变量的梯度下降
假设一个双变量函数:
$$J(x,y) = x^2 + \sin^2(y)$$
我们的目的是找到该函数的最小值,于是计算其微分:
$${\partial{J(x,y)} \over \partial{x}} = 2x$$
$${\partial{J(x,y)} \over \partial{y}} = 2 \sin y \cos y$$
假设初始位置为:
$$(x_0,y_0)=(3,1)$$
假设学习率:
$$\eta = 0.1$$
根据公式(1),迭代过程是的计算公式:
$$(x_{n+1},y_{n+1}) = (x_n,y_n) - \eta \cdot \nabla J(x,y)$$
$$ = (x_n,y_n) - \eta \cdot (2x,2 \cdot \sin y \cdot \cos y) \tag{1}$$
根据公式(1),假设终止条件为 $J(x,y)<0.01$,迭代过程如表2-3所示。
| 迭代次数 | x | y | J(x,y) |
|---|---|---|---|
| 1 | 3 | 1 | 9.708073 |
| 2 | 2.4 | 0.909070 | 6.382415 |
| … | … | … | … |
| 15 | 0.105553 | 0.063481 | 0.015166 |
| 16 | 0.084442 | 0.050819 | 0.009711 |
迭代16次后,$J(x,y)$ 的值为 $0.009711$,满足小于 $0.01$ 的条件,停止迭代。
python代码:
1 | import numpy as np |
运行结果三维曲面:

学习率η的选择
在公式表达时,学习率被表示为$\eta$。在代码里,我们把学习率定义为learning_rate,或者eta。针对上面的例子,试验不同的学习率对迭代情况的影响,如表2-5所示。
| 学习率 | 迭代路线图 | 说明 |
|---|---|---|
| 1.0 |  |
学习率太大,迭代的情况很糟糕,在一条水平线上跳来跳去,永远也不能下降。 |
| 0.8 |  |
学习率大,会有这种左右跳跃的情况发生,这不利于神经网络的训练。 |
| 0.4 |  |
学习率合适,损失值会从单侧下降,4步以后基本接近了理想值。 |
| 0.1 | 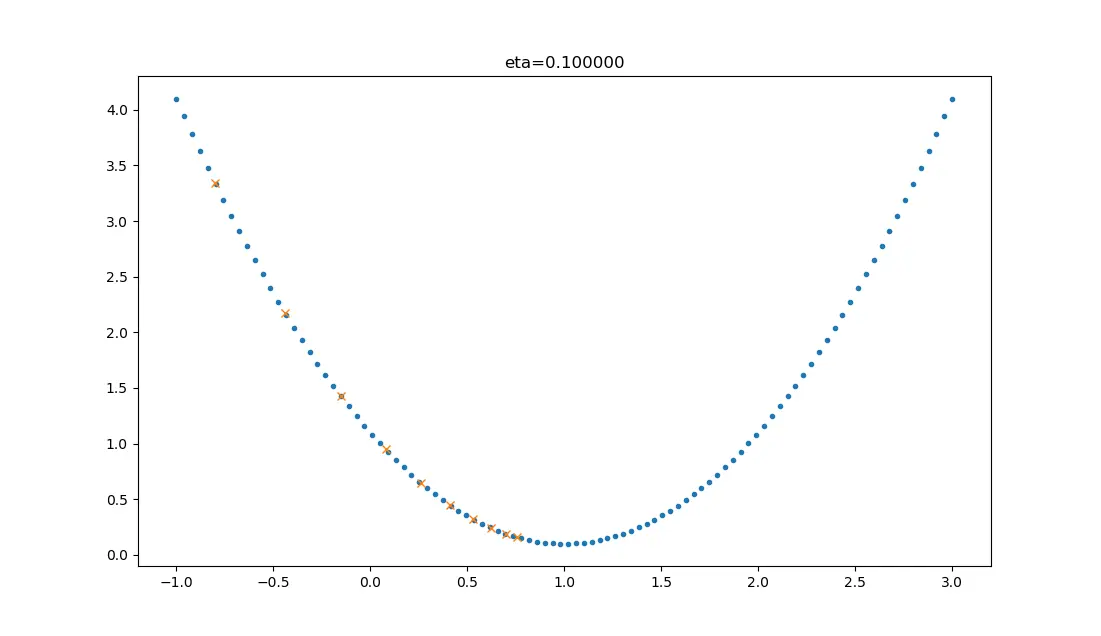 |
学习率较小,损失值会从单侧下降,但下降速度非常慢,10步了还没有到达理想状态。 |
损失函数
在最优化,统计学,计量经济学,决策论,机器学习和计算神经科学的领域中,损失函数或成本函数是指一种将一个事件(在一个样本空间中的一个元素)映射到一个表达与其事件相关的经济成本或机会成本的实数上的一种函数,借此直观表示的一些”成本”与事件的关联。一个最佳化问题的目标是将损失函数最小化。一个目标函数通常为一个损失函数的本身或者为其负值。当一个目标函数为损失函数的负值时,目标函数的值寻求最大化。
“损失”就是所有样本的“误差”的总和,亦即($m$ 为样本数):
$$损失 = \sum^m_{i=1}误差_i$$
$$J = \sum_{i=1}^m loss_i$$
机器学习常用损失函数
符号规则:$a$ 是预测值,$y$ 是样本标签值,$loss$ 是损失函数值。
- Gold Standard Loss,又称0-1误差
$$
loss=\begin{cases}
0 & a=y \\
1 & a \ne y
\end{cases}
$$
- 绝对值损失函数
$$
loss = |y-a|
$$
- Hinge Loss,铰链/折页损失函数或最大边界损失函数,主要用于SVM(支持向量机)中
$$
loss=\max(0,1-y \cdot a) \qquad y=\pm 1
$$
- Log Loss,对数损失函数,又叫交叉熵损失函数(cross entropy error)
$$
loss = -[y \cdot \ln (a) + (1-y) \cdot \ln (1-a)] \qquad y \in \{ 0,1 \}
$$
- Squared Loss,均方差损失函数
$$
loss=(a-y)^2
$$
- Exponential Loss,指数损失函数
$$
loss = e^{-(y \cdot a)}
$$
损失函数图像理解
用二维函数图像理解单变量对损失函数的影响

图gd2d中,纵坐标是损失函数值,横坐标是变量。不断地改变变量的值,会造成损失函数值的上升或下降。而梯度下降算法会让我们沿着损失函数值下降的方向前进。
- 假设我们的初始位置在 $A$ 点,$x=x_0$,损失函数值(纵坐标)较大,回传给网络做训练;
- 经过一次迭代后,我们移动到了 $B$ 点,$x=x_1$,损失函数值也相应减小,再次回传重新训练;
- 以此节奏不断向损失函数的最低点靠近,经历了 $x_2,x_3,x_4,x_5$;
- 直到损失值达到可接受的程度,比如 $x_5$ 的位置,就停止训练。
用等高线图理解双变量对损失函数影响

图gd3d中,横坐标是一个变量 $w$,纵坐标是另一个变量 $b$。两个变量的组合形成的损失函数值,在图中对应处于等高线上的唯一的一个坐标点。$w,b$ 所有不同值的组合会形成一个损失函数值的矩阵,我们把矩阵中具有相同(相近)损失函数值的点连接起来,可以形成一个不规则椭圆,其圆心位置,是损失值为 $0$ 的位置,也是我们要逼近的目标。
这个椭圆如同平面地图的等高线,来表示的一个洼地,中心位置比边缘位置要低,通过对损失函数值的计算,对损失函数的求导,会带领我们沿着等高线形成的梯子一步步下降,无限逼近中心点。
神经网络中常用的损失函数
均方差函数,主要用于回归(Regression)
交叉熵函数,主要用于分类(Classification)
二者都是非负函数,极值在底部,用梯度下降法可以求解。
学习心得
通过本章结我了解到神经网络(Neural Networks)的基础知识。人工智能的学者通过构建神经元模型来进行模拟真正的神经元,而将多个独立的神经元叠加起来,就获得了一个类神经网络,这么一个神经网络拥有的一部分神奇的地方在于,你只需要输入x,就能得到输出y,所有的中间训练过程机器都会自己完成。
如果你想要更多的学习可以看大佬的讲解




